
About the SharedMemory library
The SharedMemory class library provides a set of C# classes that utilise a non-persisted memory-mapped file for very fast low-level inter-process communication (IPC) to share data using the following data structures: buffer, array and circular buffer (also known as a ring buffer).
SharedMemory uses the MemoryMappedFile class introduced in .NET 4, and provides a partial P/Invoke wrapper around the Windows API for versions prior to this. The library was originally inspired by the following CodeProject article: “Fast IPC Communication Using Shared Memory and InterlockedCompareExchange“.
The library abstracts the use of the memory mapped file, adding a header that includes information about the size of the shared memory region so that readers are able to open the shared memory without knowing the size before hand. A helper class to support the fast copying of C# fixed-size structures in a generic fashion is also included.
The project source can be found on GitHub, with binaries available via Nuget.
What is a memory mapped file?
A memory-mapped file is an area of virtual memory that may have been mapped to a physical file and can be read from and written to by multiple processes on the same system. The file or portions thereof are accessed via views to one or more processes as a contiguous block of memory. Each view can then be read/written to using a memory location.
A memory-mapped file can be created as one of two types:
- persisted: mapped to a physical file, and
- non-persisted: in-memory only, commonly used for inter-process communication (IPC).
A memory-mapped file is referenced using a unique name, unlike named pipes however a memory-mapped file cannot be accessed directly over a network.
The Circular Buffer
I began this project when I couldn’t find a good .NET implementation of a circular buffer in order to implement fast double/n-buffered transfer of image data between processes. The lock-free approach to thread synchronisation presented in the above article appealed to me, however it had a number of limitations and bugs that had to be overcome such as only supporting a minimum of 3 nodes rather than 2.
A circular buffer, circular queue, cyclic buffer or ring buffer is a data structure that uses a single, fixed-size buffer as if it were connected end-to-end. – Wikipedia
To achieve a lock-free implementation, a single node header and multiple node records are used to keep track of which nodes within the buffer are available to be written to, those that are currently being written to, and the nodes that are currently being read from. Thread synchronisation is performed by using a combination of Interlocked.CompareExchange and EventWaitHandle‘s.
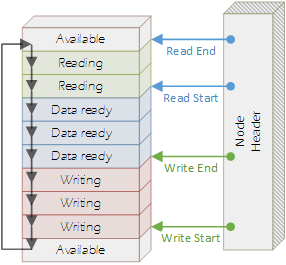
Each node is essentially a set of integers indicating the node’s index within the buffer, flags for whether it is ready to be written to or read from, and the offset within the shared memory buffer where the data for the node is actually located.

Performance
The maximum bandwidth achieved was approximately 20GB/s, using 20 nodes of 1MB each with 1 reader and 1 writer. The .NET 3.5 implementation is markedly slower, I believe this is due to framework level performance improvements.
The following chart shows the bandwidth achieved in MB/s using a variety of circular buffer configurations, ranging from 2 nodes to 50 nodes with a varying number of readers/writers, comparing a 1KB vs 1MB node buffer size on .NET 3.5 and .NET 4.
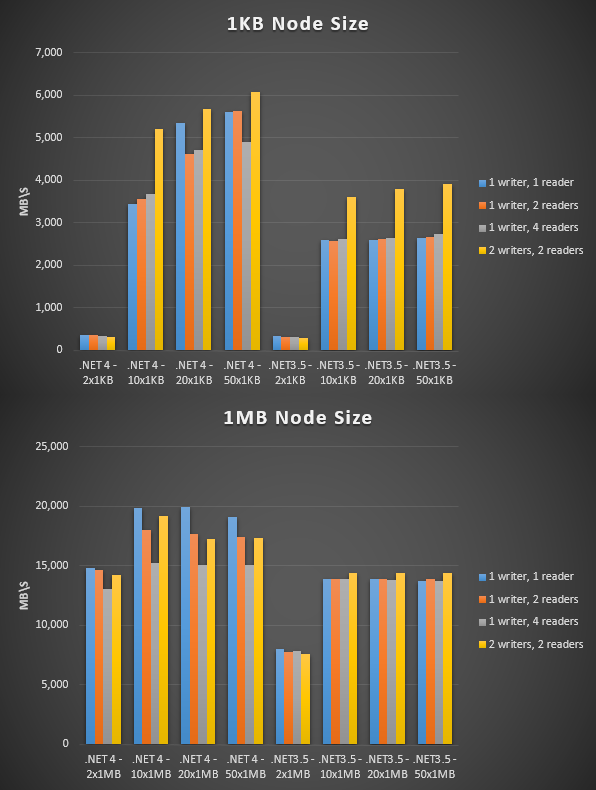
All results are from a machine running Windows 10 64-bit, Intel Core i7-3770K @ 3.50GHz, 16GB DDR3@1200MHz on an ASUS P8Z77-V. The data transferred was selected randomly from an array of 256 buffers that had been populated with random bytes.
The SharedMemory classes
- SharedMemory.Buffer – an abstract base class that wraps the MemoryMappedFile class, exposing read/write operations and implementing a small header to allow clients to open the shared buffer without knowing the size beforehand.
- SharedMemory.BufferWithLocks – an abstract class that extends SharedMemory.Buffer to provide simple read/write locking support through the use of EventWaitHandles .
- SharedMemory.Array – a simple generic array implementation utilising a shared memory buffer. Inherits from SharedMemory.BufferWithLocks to provide support for thread synchronisation.
- SharedMemory.BufferReadWrite – provides read/write access to a shared memory buffer, with various overloads to support reading and writing structures, copying to and from IntPtr and so on. Inherits from SharedMemory.BufferWithLocks to provide support for thread synchronisation.
- SharedMemory.CircularBuffer – lock-free FIFO circular buffer implementation (aka ring buffer). Supporting 2 or more nodes, this implementation supports multiple readers and writers. The lock-free approach is implemented using Interlocked.Exchange and EventWaitHandles .
- SharedMemory.FastStructure – provides a method of fast generic structure reading/writing using generated IL with DynamicMethod.
Examples
The combined output of the of the following examples is:
SharedMemory.Array: 123 456 SharedMemory.CircularBuffer: 123 456 SharedMemory.BufferReadWrite: 123 456
For more complex usage examples see the unit tests and the client/server sample in the library’s source code.
SharedMemory.Array
Console.WriteLine("SharedMemory.Array:");
using (var producer = new SharedMemory.Array<int>("MySharedArray", 10))
using (var consumer = new SharedMemory.Array<int>("MySharedArray"))
{
producer[0] = 123;
producer[producer.Length - 1] = 456;
Console.WriteLine(consumer[0]);
Console.WriteLine(consumer[consumer.Length - 1]);
}
SharedMemory.CircularBuffer
Console.WriteLine("SharedMemory.CircularBuffer:");
using (var producer = new SharedMemory.CircularBuffer(name: "MySharedMemory", nodeCount: 3, nodeBufferSize: 4))
using (var consumer = new SharedMemory.CircularBuffer(name: "MySharedMemory"))
{
// nodeCount must be one larger than the number
// of writes that must fit in the buffer at any one time
producer.Write<int>(new int[] { 123 });
producer.Write<int>(new int[] { 456 });
int[] data = new int[1];
consumer.Read<int>(data);
Console.WriteLine(data[0]);
consumer.Read<int>(data);
Console.WriteLine(data[0]);
}
SharedMemory.BufferReadWrite
Console.WriteLine("SharedMemory.BufferReadWrite:");
using (var producer = new SharedMemory.BufferReadWrite(name: "MySharedBuffer", bufferSize: 1024))
using (var consumer = new SharedMemory.BufferReadWrite(name: "MySharedBuffer"))
{
int data = 123;
producer.Write<int>(ref data);
data = 456;
producer.Write<int>(ref data, 1000);
int readData;
consumer.Read<int>(out readData);
Console.WriteLine(readData);
consumer.Read<int>(out readData, 1000);
Console.WriteLine(readData);
}
SharedMemory.FastStructure
FastStructure.PtrToStructure<T> performs approximately 20x faster than
System.Runtime.InteropServices.Marshal.PtrToStructure(IntPtr, Type) (8ms vs 160ms) and about 1.6x slower than the non-generic equivalent (8ms vs 5ms).
FastStructure.StructureToPtr<T> performs approximately 8x faster than System.Runtime.InteropServices.Marshal.StructureToPtr(object, IntPtr, bool) (4ms vs 34ms).
IntPtr destination = someTargetMemoryLocation; var buffer = new MyStructureType[somelength]; ... // using FastStructure to copy an array of struct to a memory location FastStructure.WriteArray<MyStructureType>(destination, buffer, 0, buffer.Length); // Load the first element written to destination into a structure MyStructureType myStruct = new MyStructureType(); FastStructure.PtrToStructure<MyStructureType>(ref myStruct, destination);
Downloads
The project source can be found on GitHub and Codeplex, with binaries available via Nuget and Codeplex.
Justin,
Very cool utility and one that I plan on using in an application as it sort of reminds me of the old days as a Unix type. I have run the examples and the numbers do not match. For example in the SingleProcess example if I use one writer, one reader, buffer size of 8294400 and the default number of elements the Diff value is always greater than 0. Does this mean that data was lost? Is Diff a measurement of the number of data items lost? Using the Client/Server they do not read and write the same number. Is this a problem?
Hi Douglas, this is normal. A “Diff” value in this sample indicates how many items the reader is lagging behind the writer. Can you confirm if the very last entry has a “Diff” value of 0? This indicates that the reader has caught up and the correct number have been processed.
Hi Justin, I used your project Direct3DHook to capture a continuous image stream from a DirectX application. Finally I got it to work and it is surprisingly pretty fast. However, there is still a small delay in the capture process and I really want to achieve a speed near to real time. I know that these delay is coming from the fact that your sample application is requesting each frame individually.
You mentioned your SharedMemory project in one of your comments (http://spazzarama.com/2011/03/14/c-screen-capture-and-overlays-for-direct3d-9-10-and-11-using-api-hooks/#comment-3784). So I thought it would be worth to look into it.
I’m not an expert in IPC so, do you have an example anywhere of how you can use this library to send images from one process to another? Which buffer would be the best for this purpose and what buffer size should I choose? In your examples you are exchanging some integer values but how can I exchange a byte array which have a length of 1000000, for example (depends on the image size)? Many thanks for your help.
Hi Florian,
You will want to use the CircularBuffer or BufferReadWrite, I usually have X bytes at the start for the frame header (e.g. timestamp, id, width/height), then the image data located directly after that. The node/buffer size would be the size of the header struct + image height* image stride.
e.g. FastStructure.Size + imageByteCount
If using a BufferReadWrite you would write to it like this:
if (imageBuffer.AcquireWriteLock(100)).Size, FastStructure .Size);
{
imageBuffer.Write(ref header);
imageBuffer.Write(ptrToImageData, size – FastStructure
}
You would read it like:
if (imageBuffer.AcquireReadLock(100)) {
imageBuffer.Read(out header);
if (header.Height > 0 && header.Id != previousImageId) {
previousImageId = dets.Id;
imageBuffer.Read((ptr) => {.Size);
// do stuff with the image ptr
}, FastStructure
}
}
A circular buffer will work similar, except you can only call .Read once for each frame, so you would to a read and get the IntPtr and then read stuff from that.
Tank you for your quick reply.
In your write example, as far as I have understood it correctly, the ref header is a struct containing some meta data of the image but was is the “FastStructure.Size” and where is it coming from? Is the ptrToImageData a pointer to the byte array of the image, and if yes what would be the fastest way to get the byte array, with Marshal.Copy?
And one general question, I have to create the producer SharedMemory in the client and the consumer in the process of the injected application right? What should I choose the buffer size in the client, because as I said it is dependent on the resolution of the captured image which I don’t know at the beginning. The max resolution which I would like to support is 1920*1080 so should I use the maximum amount for the buffer for that resolution even if I don’t need the whole buffer when the image has a lower resolution?
Many thanks for your help.